Muchos de los que me conocen saben que soy fiel a las certificaciones y como siempre digo, no es el papel con el aprobado lo que importa sino todo el proceso de prepararse para presentar y aprobar el examen lo que realmente vale, ya que es durante este proceso que empezamos a conocer, a meternos en las entrañas de un software, lenguaje de programación o plataforma, es decir, sencillamente salimos de nuestra zona de confort y empezamos a hacernos preguntas fuera de lo común y buscamos sus respectivas respuestas (de haberlas) o buscamos soluciones alternativas (también de haberlas), todo eso deriva en APRENDIZAJE.
Insisto me encantan las certificaciones pero porque para mí significan plantearme un reto y demostrarme a mí mismo que soy capaz de seguir aprendiendo, que si puedo aprender un nuevo lenguaje, que todavía tengo la fuerza y las ganas de superación para actualizarme en alguna tecnología en especial. Con el pasar del tiempo les confieso que cada vez se me ha hecho más difícil el intentar plantearme un reto de este tipo, por razones como la escasez de tiempo, la cantidad de trabajo, o el aprender en un marco muy estricto, pero creo que ya ha llegado la hora de proponerme otro de esos retos y que ya les contaré si lo consigo o no y es preparar la certificación Databricks Certified Associate Developer for Apache Spark 3.0. Por qué esta certificación y no otra:
Investigar las nuevas características de Spark 3.0.
El contenido a evaluar: Selección, renombrado y eliminación de columnas. Filtrado, ordenamiento y agregación. Join, lectura y escritura en distintos formatos, UDF y funciones SQL.
Poder evaluarme con Scala.
Contar con material de referencia previo.
A su vez una razón de peso para mí es que al presentarla y aprobarla, esto motive a la gente que trabaja conmigo para que a su vez sientan ese deseo por aprender y especializarse e incluso no comentan los mismos errores que yo y que al menos ya cuenten con algo de material de apoyo para empezar.
El material de referencia que utilizaré para prepararme serán los libros:
Learning Spark 2nd Edition (Sobre todo para aprender todo lo nuevo de Spark 3.0).
Spark the definitive guide.
A su vez sigo el blog de Databricks que cada tanto comparte información importante sobre todo referente a cómo funciona Spark.
Por último he comenzado a crear una serie de notebooks con ejemplos muy simples (tanto en Scala como Python) que comparto con todos intentando abarcar todo el contenido.
Aquí les dejo el enlace espero que sea de ayuda y les motive a aprender y afrontar esta certificación e incluso les motive a seguir. Este mes es mi cumpleaños y dudo que me dé una paliza repasando pero quizás (y por eso lo comparto para crear una especie de compromiso) me disponga a presentar en abril y espero poder aprobar a la primera.
Quienes me conocen saben que soy fan de IntelliJ, ya llevo unos cuantos años desde que dejé de usar eclipse y la verdad es que estoy encantado con la decisión que tomé, para mí es la mejor herramienta para desarrollo Java, Scala (y supongo que Kotlin).
Actualmente Spark está en mi día a día ya sea a modo desarrollo programando en Scala, razón por la cual uso continuamente IntelliJ sino también en la formación tanto en Scala como en Python, hasta hace poco para las formaciones de PySpark (entiéndase Spark con el API de Python) utilizaba los Jupyter notebooks (e incluso la plataforma de Databricks pero eso da para otra entrada en el blog) pero estaba la curiosidad que poco a poco se ha convertido en una necesidad de contar con una herramienta más potente que permitiese hacer debug, que integrase Git, hacer markdown, autocompletado de código, permita estandarizar el código, etc. Si lo meditan un poco casi todo de una forma u otra se puede alcanzar con los Jupyter notebooks, pero lo que cambia es la forma de programación, ya que con un IDE sería programación al uso (sea esta funcional o no), mientras que con los notebooks sería programación literaria, es decir, un entorno más enfocado a la explicación y documentación del código y hoy en día ampliamente utilizado por científicos de datos (data scientists), mientras que el primero (IDE) más utilizado por los ingenieros de datos (data engineer).
Finalmente nos hemos puesto manos a la obra en probar varios IDEs en el equipo y yo no quise desperdiciar la oportunidad de trastear con PyCharm y hacer mis primeras pruebas de programación de PySpark y es lo que comparto ahora con ustedes.
Antes que nada hay ciertos requisitos previos:
Tener instalado Spark
Tener instalado Python
Está vez no les voy a mostrar como instalar Spark, ya que hay muchísimas fuentes que nos explican como hacerlo pero en cualquier caso hay que tener claro que es necesario Java 8 (al menos) y declarar las variables de entorno SPARK_HOME y HADOOP_HOME, la primera apuntando a la ruta de la instalación de Spark y la segunda a la ruta base de donde se instalará el winutils.
El otro requisito es Python, hay distintas formas de instalar python que tampoco explicaré aquí, pero resumiendo puede ser instalando el lenguaje (y luego pip si se desea o es necesario instalar otra dependencia) o mediante anaconda, yo he elegido este último ya que es un entorno que trae consigo ya instalado jupyter notebooks además de otras herramientas, en cualquier caso si alguien tiene cierta curiosidad de cuando instalar pip o anaconda les dejo este articulo de stackoverflow que no tiene desperdicio.
Anaconda y sus aplicaciones
Ya entrando en materia, el primer paso es descargar e instalar PyCharm (este podría incluso llegar a instalarse desde Anaconda, yo preferí descargarla para contar con la versión mas reciente). Yo lo hice con la versión community
Una vez instalado y ejecutado por primera vez, crearemos un nuevo proyecto y deberemos especificar nuestro entorno (environment), yo soy de los que prefiere crear un entorno por proyecto debido a que cada proyecto python (en general) puede ser diferente en cuanto a dependencias características, etc. llegando incluso a diferir la versión de python entre 2 y 3. A su vez dejo marcada la opción de que genere un main.py tal cual como aparece en las imágenes.
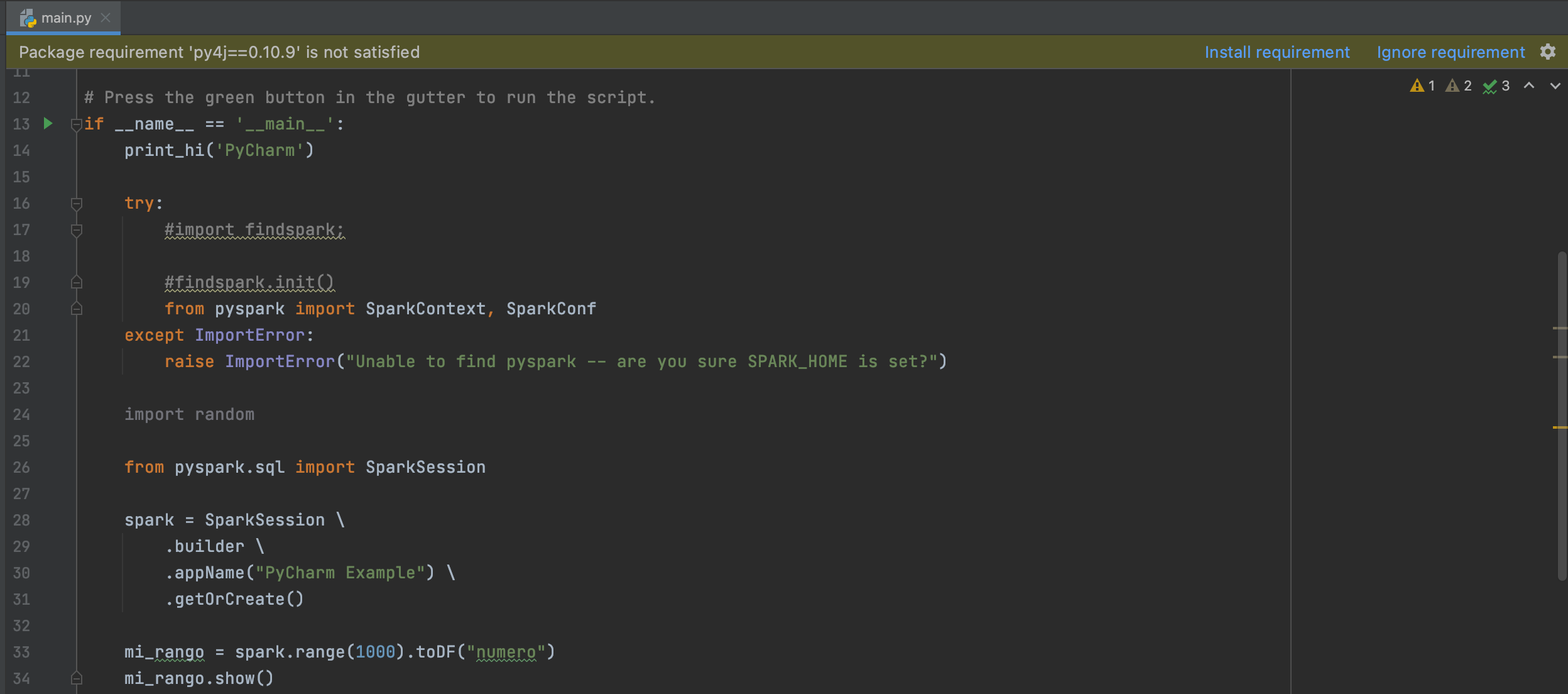
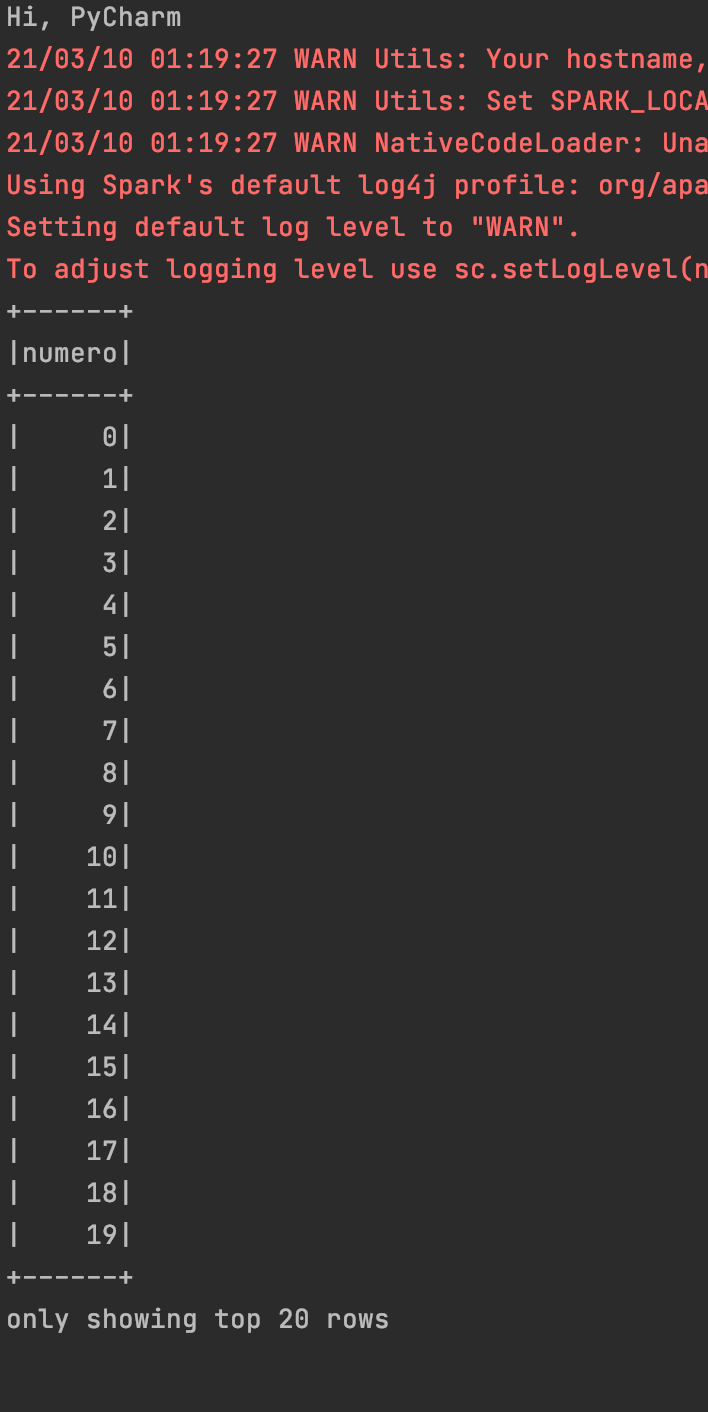
El IDE nos genera un main.py que hace de esqueleto de la aplicación, lo editamos con un trozo de código que genera un DataFrame y mostrará parte de su contenido mediante la invocación del método show quedando de esta manera
# This is a sample Python script.
# Press ⌃R to execute it or replace it with your code.
# Press Double ⇧ to search everywhere for classes, files, tool windows, actions, and settings.
def print_hi(name):
# Use a breakpoint in the code line below to debug your script.
print(f'Hi, {name}') # Press ⌘F8 to toggle the breakpoint.
# Press the green button in the gutter to run the script.
if __name__ == '__main__':
print_hi('PyCharm')
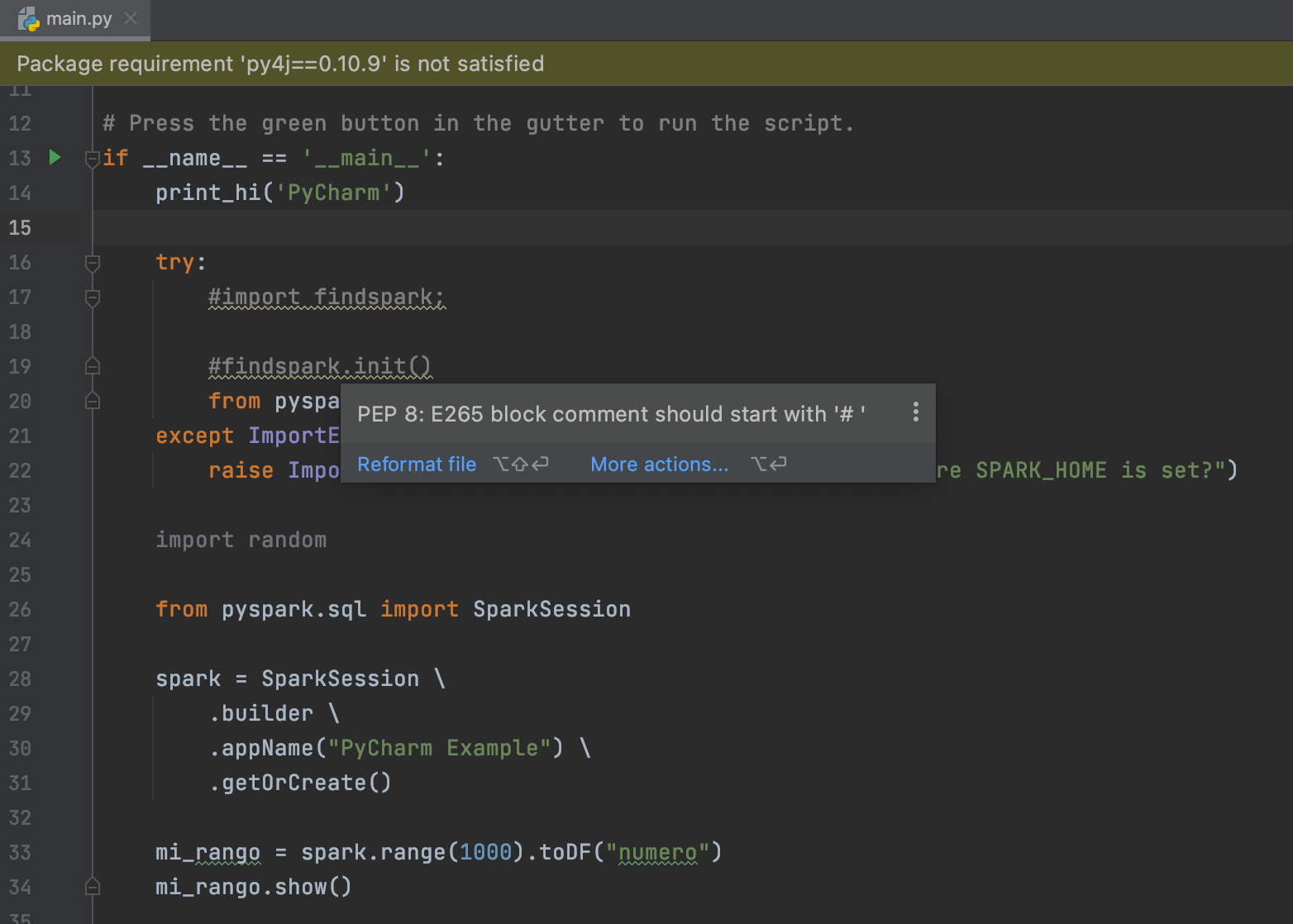
try:
#import findspark;
#findspark.init()
from pyspark import SparkContext, SparkConf
except ImportError:
raise ImportError("Unable to find pyspark -- are you sure SPARK_HOME is set?")
import random
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("PyCharm Example") \
.getOrCreate()
mi_rango = spark.range(1000).toDF("numero")
mi_rango.show()
# See PyCharm help at https://www.jetbrains.com/help/pycharm/
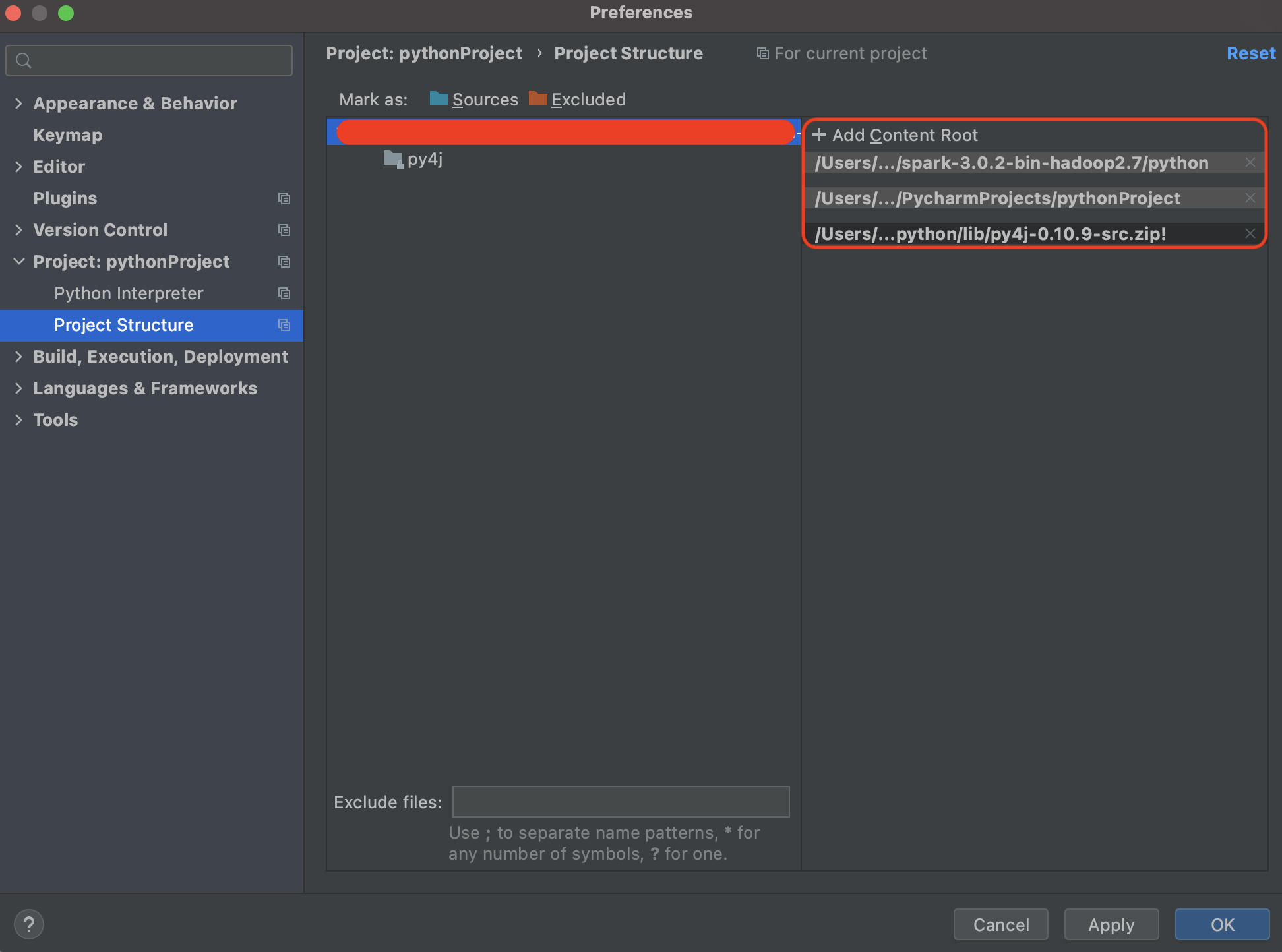
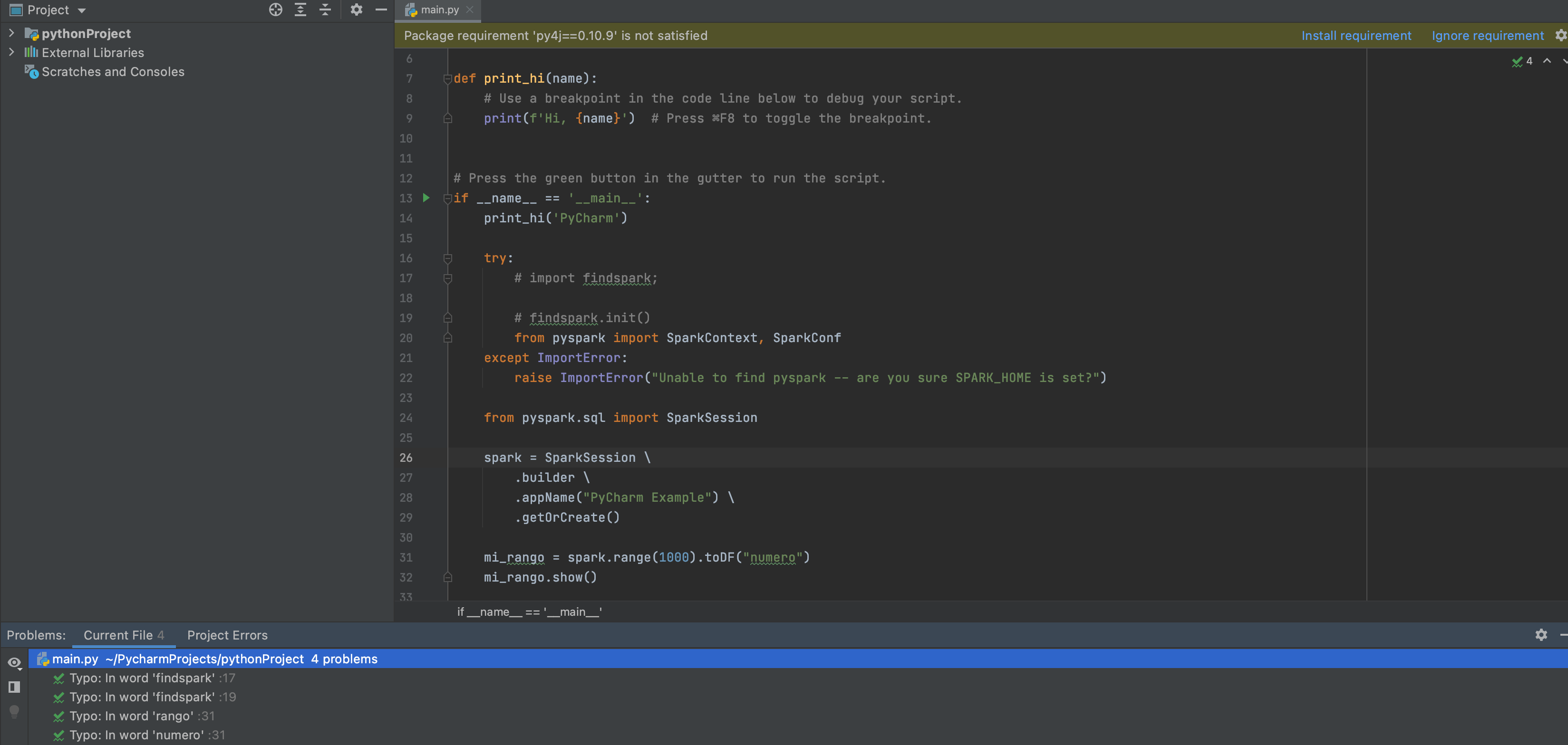
Si este código tratamos de ejecutarlo (Menu Run->Run main), este falla. Esto se debe a que es necesario incluir las dependencias propias de Spark, por lo cual es necesario incluir la carpeta python de la instalación de Spark (sería $SPARK_HOME/python) y además la carpeta py4j ubicada en $SPARK_HOME/python/lib/py4j-xxx-.zip
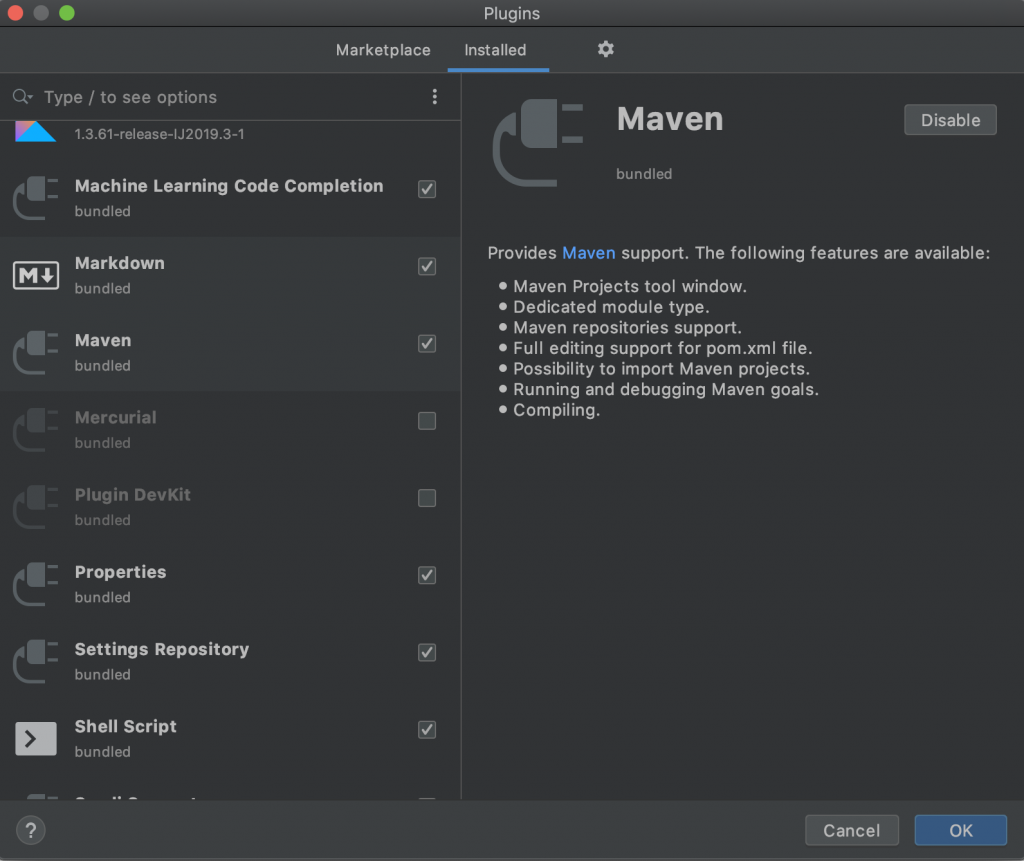
El añadir py4j es una de las alternativas que existen para poder hacer ejecuciones en local del código. Otra alternativa es instalar py4j como dependencia del entorno (environment) y de hecho la misma herramienta te ofrece la alternativa como se refleja en la imagen a continuación
Ahora podemos darnos cuenta que ya no se resaltan (en rojo) parte del código. Procedemos de nuevo a ejecutar el código y nos damos cuenta que este se ejecuta exitosamente.
Ya estamos a punto de terminar pero falta un pequeño detalle, el IDE todavía nos marca unos warnings, por ejemplo el código comentado y esto se debe a que por defecto PyCharm ya aplica PEP8 como estándar al código y por ende todo aquello que no cumpla con el estándar definido será resaltado para su corrección como se muestra en la imagen.
Incluso si hacemos clic en el símbolo de warning (cuidado) ubicado en la parte superior derecha, nos listará las cosas a mejorar que cumplan con el estándar. Una vez listado los warnings procedo mejorar el código quedando de la siguiente manera
Finalmente el código (aunque es muy simple) ya cumple con el estándar PEP8 y nos ha resultado relativamente sencillo poder ejecutar nuestro código desde el mismo IDE, además la herramienta nos permite sin salir de ella acceder a linea de comandos, hacer control total de Git (pull, push, commit, comparación entre ramas y más), poner breakpoints y realizar debug del código. Otra cosa a comentar es que aun cuando no hayamos definido el SPARK_HOME (cosa que no recomiendo) y el HADOOP_HOME, estas variables podemos definirlas antes de ejecutar el código mediante Edit Configurations.
Ha sido un ejemplo muy simple pero creo que refleja parte del potencial de la herramienta, aunque no todos son buenas noticias, por ejemplo la versión community no permite abrir y ejecutar jupyter notebooks cosa que si permite la versión de pago, llegando incluso a permitir la ejecución celda a celda y esta es una característica muy deseada que algunas herramientas si lo permiten como es el caso de VSCode, sin embargo esto no empaña para nada las capacidades que tiene y puede aportarnos de cara a la productividad.
Seguro que en alguna ocasión nos ha tocado hacer un SHOW PARTITIONS de una tabla HIVE particionada, con la finalidad (para quien no lo sepa) de obtener/visualizar las particiones existentes de los datos. Hasta aquí nada nuevo, pero lo que quiero mostrarles en esta oportunidad es un método (nada espectacular) que me ha servido mucho donde obtengo las particiones de una tabla (Hive) y los usos que le he dado al método, entre otras con grandes ventajas en performance.
Como seguramente muchos de ustedes saben si invocamos un SHOW PARTITIONS en spark por ejemplo en la spark-shell, esta nos devuelve un DataFrame con una única columna, como el siguiente ejemplo:
Con mi método lo que hago es transformar el DataFrame original en uno formateado donde cada variable de particionado es una columna. A continuación el método y el que sería el DataFrame resultante
Ahora ustedes se preguntarán y que hay de fascinante o interesante en este método. La verdad que el método en sí aporta poco es sencillamente una simple transformación pero para mí la magia reside en para que lo utilizo y es lo que les quiero contar.
Imaginen que la tabla que posee las 5 variables de partición (ni discutamos si es acertado poseer 5 variables de particionamiento) posee un sin fin de particiones y que a su vez para una misma ciudad en una misma fecha hay varias particiones por hora (como aparece en el ejemplo para la ciudad de Valencia) y cada partición a su vez tiene muchos registros. Con este supuesto si quisiéramos hacer una consulta para obtener la máxima partición (la más reciente) para una fecha, ciudad, estado y país en especifico podríamos llegar a tener problemas de TimeOut o SocketTimeOut ya que: * El cluster se vería exigido intentando trabajar sobre las particiones pertinentes (debido al gran número de particiones). * Una vez obtenidas las particiones cargar los datos desde HDFS y recorrer de forma innecesaria un conjunto de datos requiriendo mucho más memoria de la necesaria.
¿Recorrer de forma innecesaria? Si, ya que recorreríamos un conjunto de registros donde muchos de esto compartirán el valor de la columna «hora» (partición) y apegándonoslos al ejemplo de arriba (la ciudad de Valencia) realmente los valores posibles serían 2: * 1700 * 1750
Solución: Pues al obtener el DataFrame de particiones, si posteriormente filtramos por país, estado, ciudad y día solo nos quedarían 2 registros para el campo hora y sencillamente tendría que hallar el máximo valor de 2 registros en vez de tener que cargar datos de HDFS e iterar sobre todos estos.
¿Mucha más memoria de la necesaria? Si, ya que al hacer un SHOW PARTITIONS, nosotros interactuamos con el metatstore y los metadatos en vez de trabajar con todos los datos de HDFS con todo lo que eso implica en cuanto a latencia, debido a la necesidad de ir a disco, etc.
¿Existe alguna otra ventaja de trabajar con el metastore? Si, por ejemplo para hallar la máxima partición, trabajando únicamente con el DataFrame de particiones y una vez hallada la partición idónea, digamos que la más reciente, entonces construyo la consulta (muy especifica) indicando los valores de la partición deseada evitando esos errores de TimeOut haciendo uso eficiente de los recursos. De hecho yo lo que hecho es construir un WHERE dinámico (quizás lo comparto en la próxima entrada) a partir del DataFrame de particiones filtrado.
¿Se te ocurre otra ventaja de utilizar un método como este e interactuar con el metastore? ¿Habías hecho algo similar para tener mejoras de rendimiento y uso eficiente de recursos?
Este es un post que la verdad no había tenido en mente crear pero últimamente se me ha convertido en una necesidad y la verdad he disfrutado hacer y es que en estos ya casi 5 años involucrado en temas relacionados con Big Data y la nube la verdad es que he podido notar como construir un proyecto Spark desde cero se convierte en algo fácil pero netamente basado en copiar y pegar de proyectos anteriores, pero … y qué sucede cuando no hay un proyecto anterior jejeje, pero no es el único caso y qué sucede con aquellos que están aprendiendo, es cuestión de indagar por Internet y encuentras 30 formas distintas de armar un proyecto desde cero de Spark con Scala con Maven y en un IDE en este caso IntelliJ, pero cual es la idónea, cual es la que verdaderamente funciona.
Pues he decidido crear un esqueleto de proyecto (el cual espero poder ir evolucionando y mejorarlo) que seguramente no es la mejor pero desde mi humilde punto de vista es funcional.
Configurar el IDE
Lo primero antes que nada es instalar el jsdk (1.8 como mínimo), luego en la instalación o inmediatamente después es asegurarnos de contar con los plugins de Maven y Scala, para ello en la ventana de inicio vamos a los plugins.
Buscamos el plugin de Scala para verificar que este instalado si no lo está lo instalamos y luego en la misma ventana en la parte superior junto a Marketplace hacemos clic en installed y verificamos que el plugin de maven por defecto este habilitado.
Creamos el proyecto
Seleccionamos la opción de crear un nuevo proyecto.
Ventana de inicio de IntelliJ
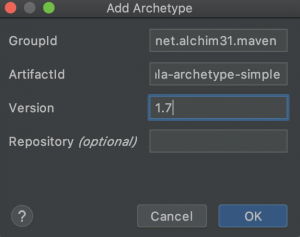
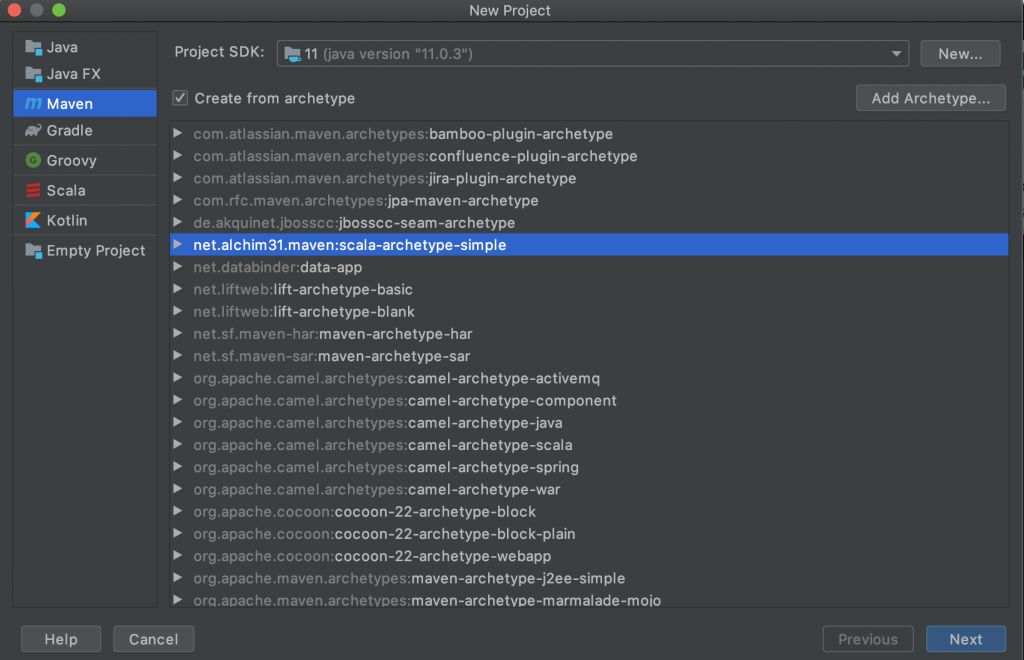
Acto seguido seleccionamos la opción de proyecto maven y marcamos la opción de Create from archetype. Seleccionamos el archetype net.alchim31.maven:scala-archetype-simple y pulsamos el botón «Next». Si el archetype no existe pulsamos el botón de Añadir Archetype (Add Archetype) cumplimentamos la información con los siguientes datos: GroupId: net.alchim31.maven ArtifactId: scala-archetype-simple Version: 1.7
Una vez añadido lo seleccionamos y como habíamos indicado antes pulsamos el botón «Next».
Indicamos el archetype en caso de no estar presente en la lista
Lista de archetypes para crear el proyecto
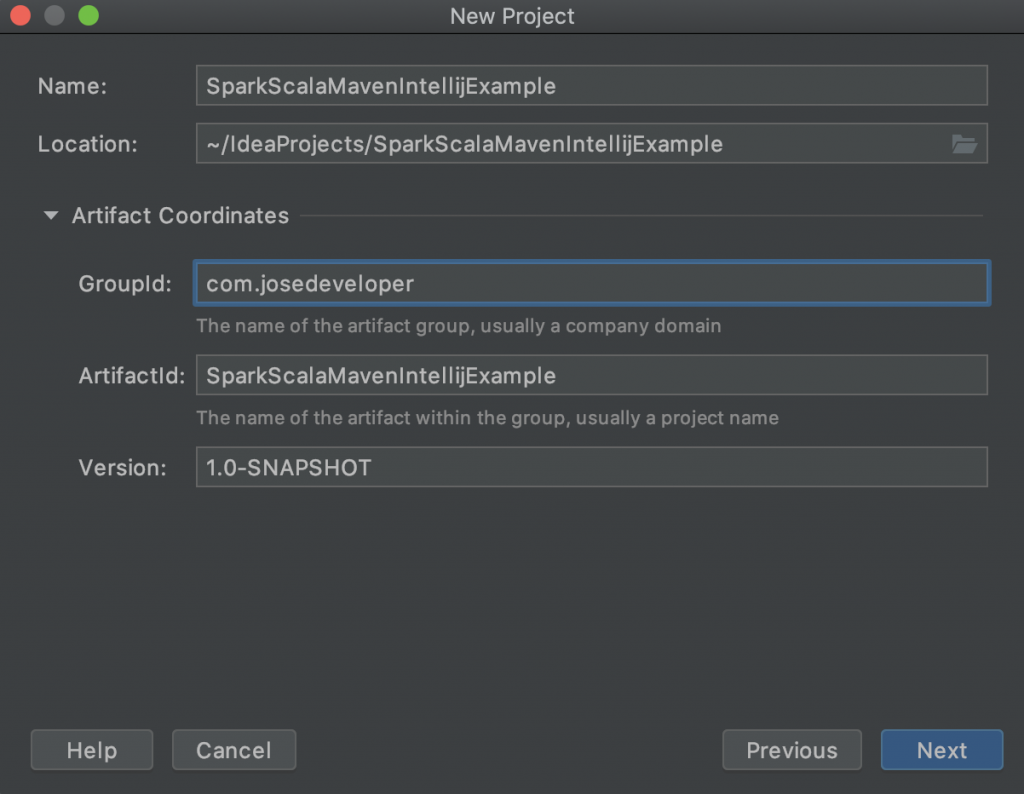
Inmediatamente después le daremos nombre a nuestro proyecto y si queremos ser más específicos indicamos el GroupId, ArtifactId y versión de nuestro proyecto (OJO esto último es opcional), pulsamos «Next» y por último en la ventana resumen pulsamos «Finish».
Configuración de nuestro artifact
Lo primero que deberemos hacer para que nos facilite la tarea será habilitar la autoimportación de las dependencias maven como señalamos en la imagen.
Habilitamos la autoimportación de dependencias
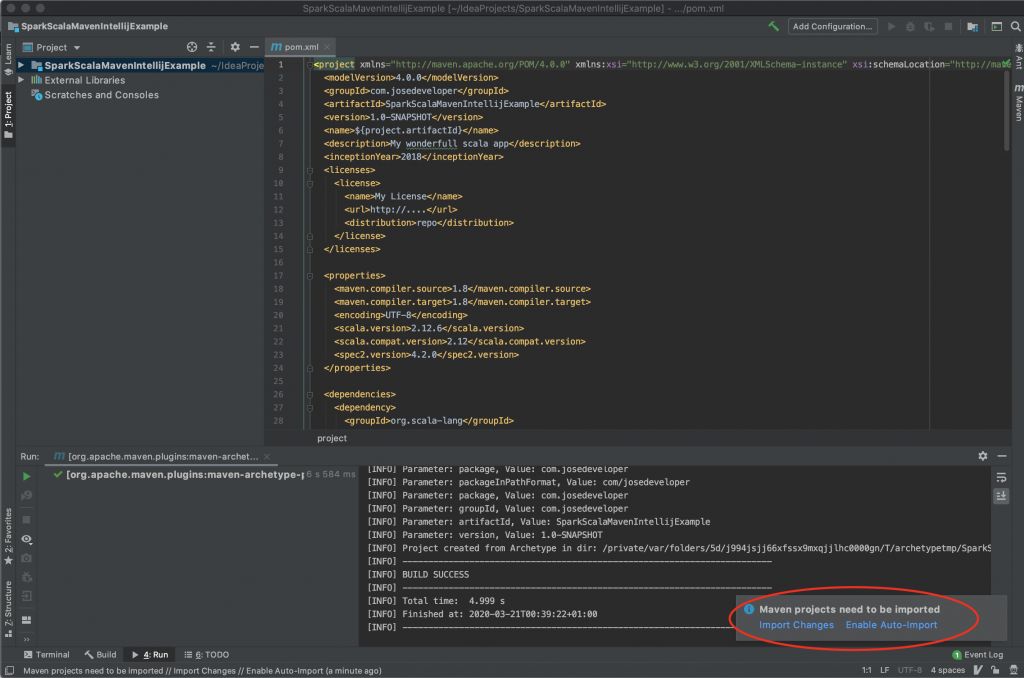
El construir el proyecto a partir de un archetype (arquetipo) maven consiste en armar el esqueleto de un proyecto a partir de una plantilla definiendo una estructura minima por defecto, por lo cual veremos un fichero pom.xml (gestión de dependencias maven) con algunas dependencias y una estructura de carpetas para el código fuente y pruebas unitarias, con ficheros incluidos.
Estructura del proyecto reciéntame creado
Aprovechamos de dar un vistazo a la clase App y a las pruebas unitarias que por defecto nos añade al proyecto e incluso podemos compilar el proyecto para contrastar que todo está de maravilla y para ello solamente necesitamos hacer clic en la pestaña maven ubicado en la parte derecha, donde aparece el nombre de nuestro proyecto desplegar lifecycle y hacer doble clic en compile y esto iniciará el proceso de compilación terminando exitosamente.
Añadimos dependencias
Ya estamos llegando al final, ahora lo que haremos será añadir al fichero pom.xml las dependencias spark que utilizaremos para este ejemplo. Empezaremos por editar las propiedades quedando estas así:
Por último modificaremos nuestra clase App quedando esta así:
Java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
packagecom.josedeveloper
importorg.apache.spark.rdd.RDD
importorg.apache.spark.sql.SparkSession
/**
* @author ${user.name}
*/
objectApp{
def main(args:Array[String]){
val spark:SparkSession=SparkSession.builder().master("local[1]")
.appName("SparkByExamples.com")
.getOrCreate()
val rdd:RDD[Int]=spark.sparkContext.parallelize(List(1,2,3,4,5))
val rddCollect:Array[Int]=rdd.collect()
println("Number of Partitions: "+rdd.getNumPartitions)
println("Action: First element: "+rdd.first())
println("Action: RDD converted to Array[Int] : ")
rddCollect.foreach(println)
}
}
Para de nuevo volver a compilar el proyecto, que deberá culminar exitosamente.
Ejecución
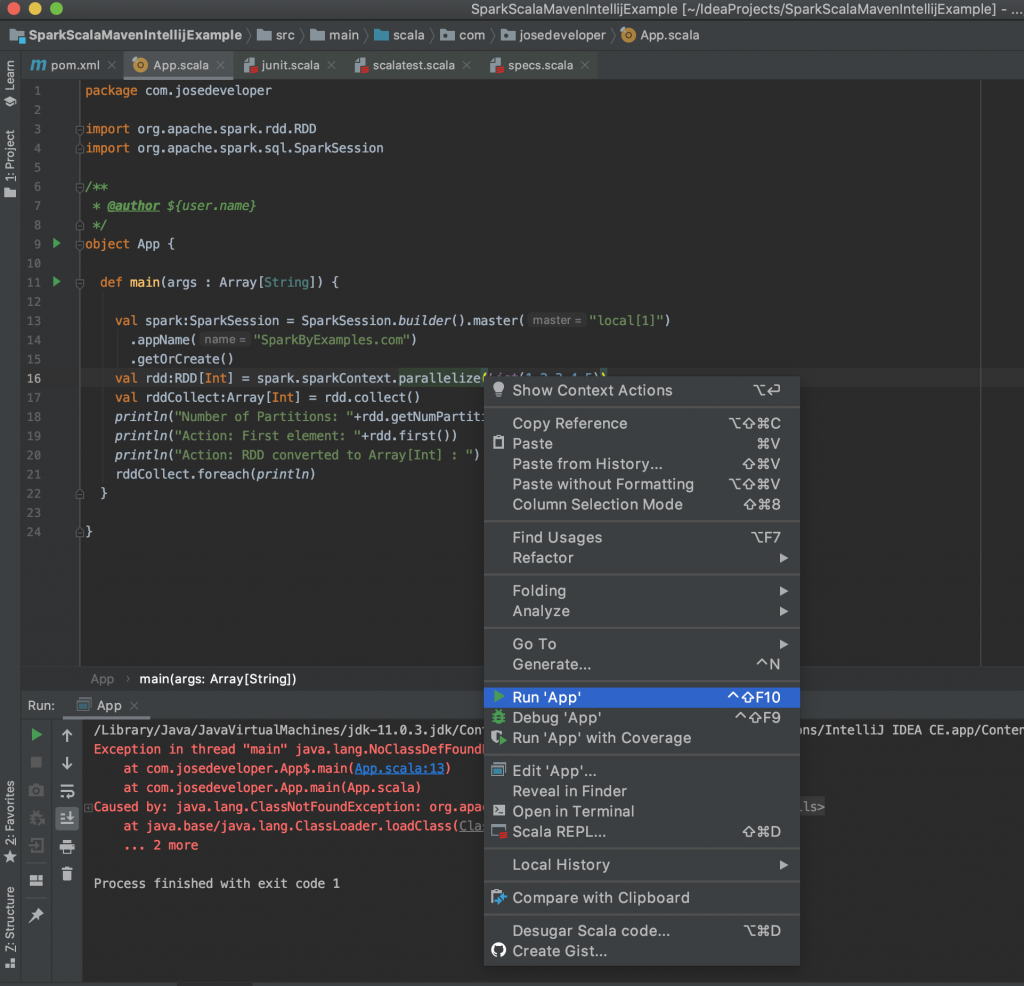
La forma que indicaremos para la ejecución de los jobs desde IntelliJ no es la mejor pero es una forma sencilla y funcional para probar cosas y sobre todo para quien comienza a hacer tests sin necesidad de empaquetar y crear un jar y desplegarlo en una máquina virtual o en un cluster. ¿Cuál sería entonces la mejor forma? A mi modo de ver las cosas la mejor forma sería mediante prueba unitarias y de integración donde podamos probar todo el job de inicio a fin y para explicarles como ya tengo en mente preparar otro post paso a paso indicando como hacerlo y las herramientas para lograrlo. Continuando con la configuración de la ejecución, si sencillamente con botón derecho del ratón hacemos clic en Run ‘App’ nos arrojará el error.
Exception in thread «main» java.lang.NoClassDefFoundError: org/apache/spark/sql/SparkSession$
at com.josedeveloper.App$.main(App.scala:13)
at com.josedeveloper.App.main(App.scala)
Caused by: java.lang.ClassNotFoundException: org.apache.spark.sql.SparkSession$
at java.base/jdk.internal.loader.BuiltinClassLoader.loadClass(BuiltinClassLoader.java:583)
at java.base/jdk.internal.loader.ClassLoaders$AppClassLoader.loadClass(ClassLoaders.java:178)
at java.base/java.lang.ClassLoader.loadClass(ClassLoader.java:521)
… 2 more
Error ejecutando la clase App
El error se debe a que no encuentra las clases con las que fue compilado previamente y eso se debe a que las dependencias de spark las hemos añadido con el alcance «provided». ¿Por qué provided? Debido a que en un entorno empresarial esas dependencias no debemos agregarlas ya que las provee la infraestructura Big Data de la empresa.
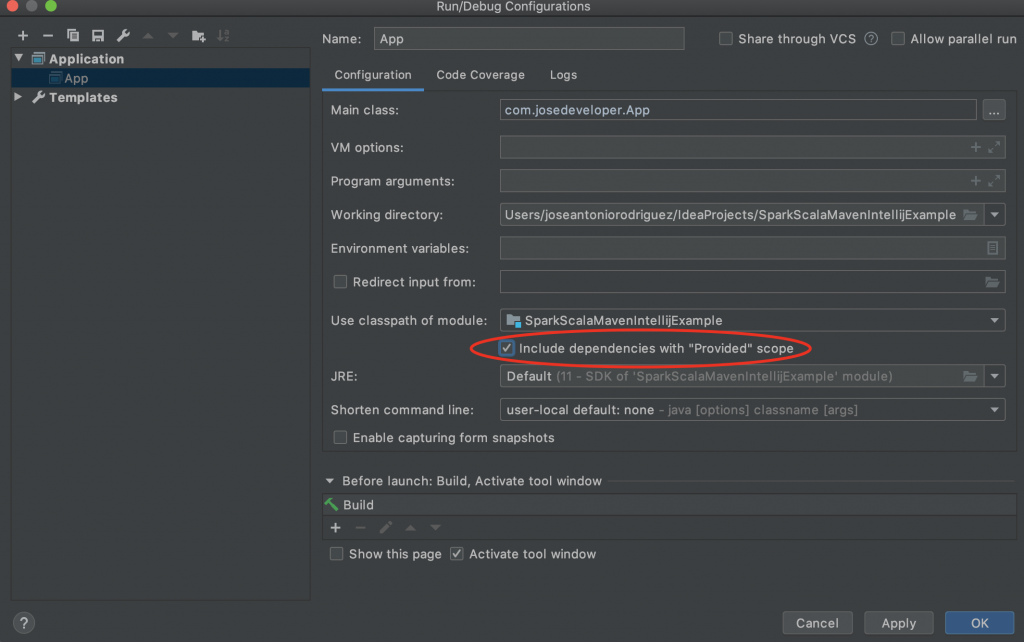
Entonces para solventar el error sencillamente debemos ir al menu «Run» y hacemos clic en «Edit Configurations» y allí marcamos la opción de incluir dependencias provided (Include dependencies with «Provided» scope).
Marcamos la opción que incluya las dependencias con alcance «Provided»
Hecho eso volvemos a ejecutar la clase App y veremos como si se logra ejecutar la aplicación. Sin más espero que les haya servido de ayuda y les comento que mi próximo paso será crear un archetype (arquetipo) y a su vez explicarles como hacerlo para que cada quien pueda construir uno acorde con las necesidades de su organización y así dotamos de más profesionalidad y agilidad nuestro trabajo y evitamos el copiar+pegar donde en ocasiones terminamos añadiendo mas dependencias y plugins innecesarios así como también arrastrando problemas y errores (de haberlos).
Sigo con mi pruebas con lo nuevo (y no tan nuevo de Spark 2), hoy comparto con ustedes una versión 2 de mi anterior post Estadística simple con Spark, pero en esta ocasión realizado con Spark 2.
¿Que tiene de nuevo esta versión?
Primeramente utiliza el módulo spark-csv lo cual nos hace más simple la carga del fichero en un Dataset. Segundo, que no manipulamos en ningún instante RDD alguno, sino que por el contrario estamos trabajando con DataFrames representados mediante la clase Dataset. Entre las cosas nuevas que contempla esta versión hecha en Spark 2 es que mientras antes al realizar un groupBy sobre un DataFrame esto nos devolvía un GroupedData ahora nos devuelve un RelationalGroupedData, esto debido a un cambio de nombre que se le ha dado a partir de esta nueva versión de Spark.
Esta nueva versión realizada con SparkSQL con Datasets tiene varias ventajas, la primera es simplicidad, es mucho mas simple, mas fácil de entender el código además de mas corto, de hecho con menos lineas obtuve más información que con la versión elaborada con RDD’s, es decir, es mas versátil. Por otro lado aunque hay que tener algo de nociones de conjuntos lo interesante es que esta versión esta libre de código SQL.
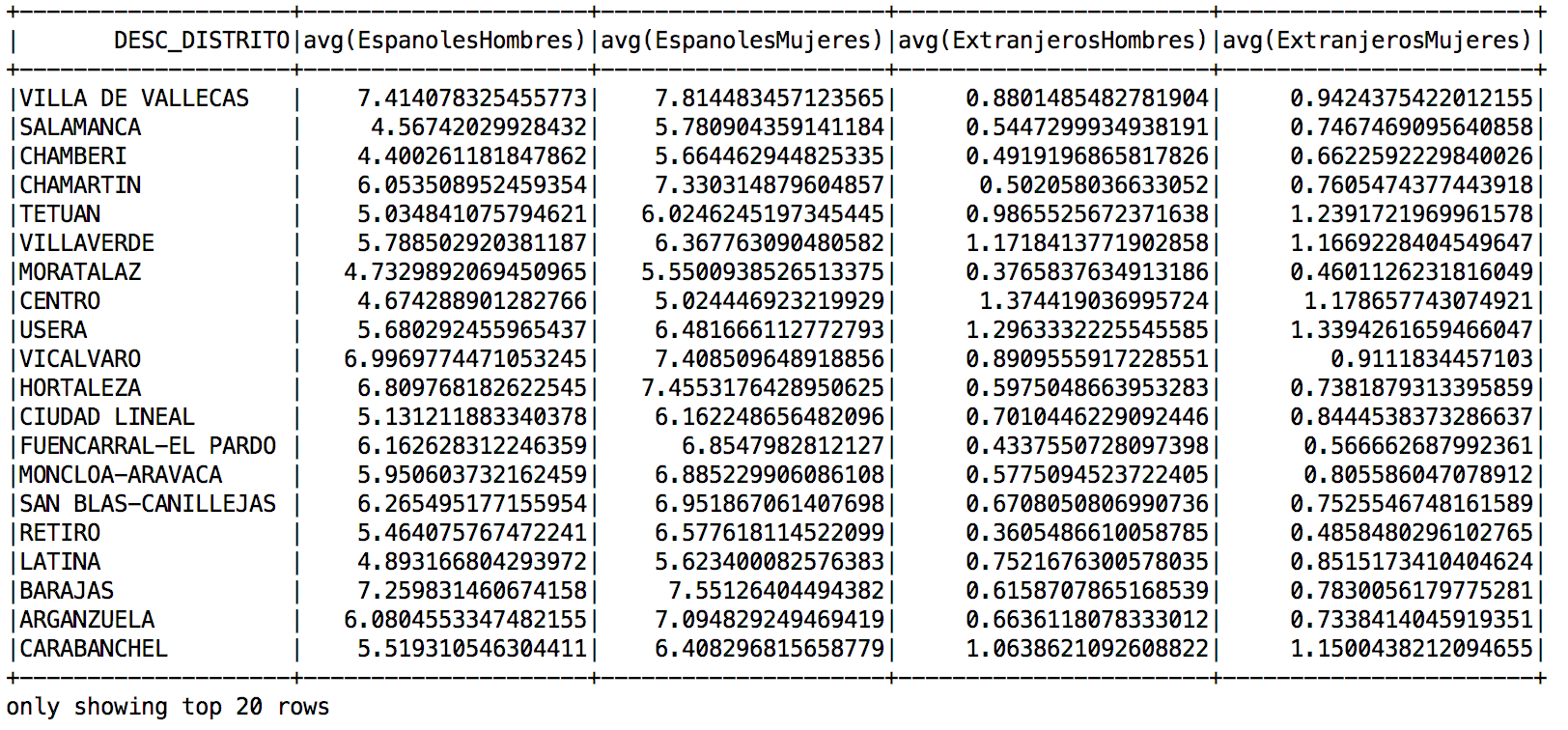
Para que comparen los resultados obtenidos aquí con respecto a la entrada anterior dejo un pantallazo de lo obtenido al ejecutarlo en mi local.
promedios por distrito
Otras agregaciones por distrito
Total personas por distrito
Uso de cookies
Este sitio web utiliza cookies para que usted tenga la mejor experiencia de usuario. Si continúa navegando está dando su consentimiento para la aceptación de las mencionadas cookies y la aceptación de nuestra política de cookies, pinche el enlace para mayor información.plugin cookies