
Quienes me conocen saben que soy fan de IntelliJ, ya llevo unos cuantos años desde que dejé de usar eclipse y la verdad es que estoy encantado con la decisión que tomé, para mí es la mejor herramienta para desarrollo Java, Scala (y supongo que Kotlin).
Actualmente Spark está en mi día a día ya sea a modo desarrollo programando en Scala, razón por la cual uso continuamente IntelliJ sino también en la formación tanto en Scala como en Python, hasta hace poco para las formaciones de PySpark (entiéndase Spark con el API de Python) utilizaba los Jupyter notebooks (e incluso la plataforma de Databricks pero eso da para otra entrada en el blog) pero estaba la curiosidad que poco a poco se ha convertido en una necesidad de contar con una herramienta más potente que permitiese hacer debug, que integrase Git, hacer markdown, autocompletado de código, permita estandarizar el código, etc. Si lo meditan un poco casi todo de una forma u otra se puede alcanzar con los Jupyter notebooks, pero lo que cambia es la forma de programación, ya que con un IDE sería programación al uso (sea esta funcional o no), mientras que con los notebooks sería programación literaria, es decir, un entorno más enfocado a la explicación y documentación del código y hoy en día ampliamente utilizado por científicos de datos (data scientists), mientras que el primero (IDE) más utilizado por los ingenieros de datos (data engineer).

Finalmente nos hemos puesto manos a la obra en probar varios IDEs en el equipo y yo no quise desperdiciar la oportunidad de trastear con PyCharm y hacer mis primeras pruebas de programación de PySpark y es lo que comparto ahora con ustedes.
Antes que nada hay ciertos requisitos previos:
- Tener instalado Spark
- Tener instalado Python
Está vez no les voy a mostrar como instalar Spark, ya que hay muchísimas fuentes que nos explican como hacerlo pero en cualquier caso hay que tener claro que es necesario Java 8 (al menos) y declarar las variables de entorno SPARK_HOME y HADOOP_HOME, la primera apuntando a la ruta de la instalación de Spark y la segunda a la ruta base de donde se instalará el winutils.
El otro requisito es Python, hay distintas formas de instalar python que tampoco explicaré aquí, pero resumiendo puede ser instalando el lenguaje (y luego pip si se desea o es necesario instalar otra dependencia) o mediante anaconda, yo he elegido este último ya que es un entorno que trae consigo ya instalado jupyter notebooks además de otras herramientas, en cualquier caso si alguien tiene cierta curiosidad de cuando instalar pip o anaconda les dejo este articulo de stackoverflow que no tiene desperdicio.

Ya entrando en materia, el primer paso es descargar e instalar PyCharm (este podría incluso llegar a instalarse desde Anaconda, yo preferí descargarla para contar con la versión mas reciente). Yo lo hice con la versión community
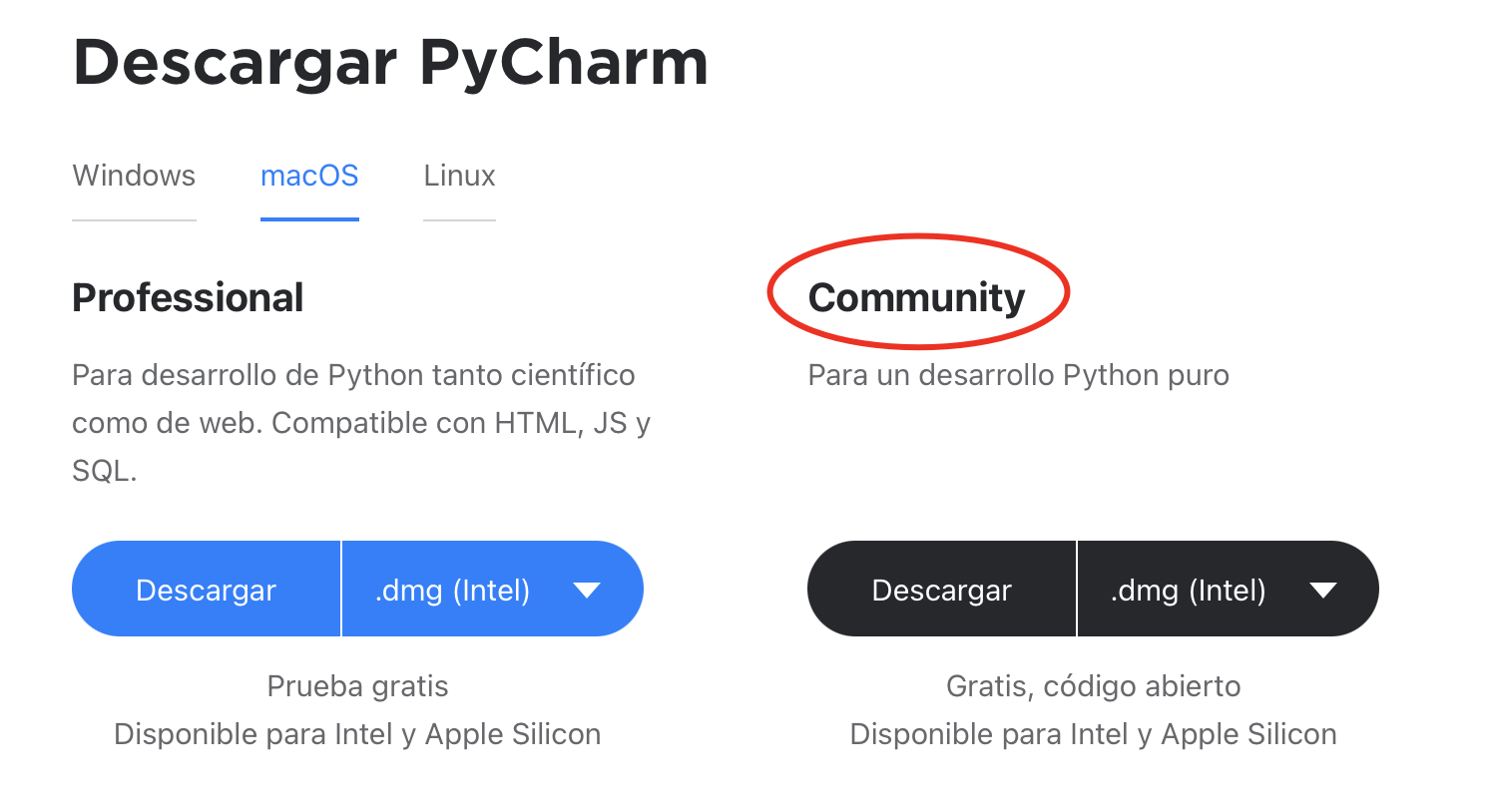
Una vez instalado y ejecutado por primera vez, crearemos un nuevo proyecto y deberemos especificar nuestro entorno (environment), yo soy de los que prefiere crear un entorno por proyecto debido a que cada proyecto python (en general) puede ser diferente en cuanto a dependencias características, etc. llegando incluso a diferir la versión de python entre 2 y 3. A su vez dejo marcada la opción de que genere un main.py tal cual como aparece en las imágenes.

El IDE nos genera un main.py que hace de esqueleto de la aplicación, lo editamos con un trozo de código que genera un DataFrame y mostrará parte de su contenido mediante la invocación del método show quedando de esta manera
# This is a sample Python script.
# Press ⌃R to execute it or replace it with your code.
# Press Double ⇧ to search everywhere for classes, files, tool windows, actions, and settings.
def print_hi(name):
# Use a breakpoint in the code line below to debug your script.
print(f'Hi, {name}') # Press ⌘F8 to toggle the breakpoint.
# Press the green button in the gutter to run the script.
if __name__ == '__main__':
print_hi('PyCharm')
try:
#import findspark;
#findspark.init()
from pyspark import SparkContext, SparkConf
except ImportError:
raise ImportError("Unable to find pyspark -- are you sure SPARK_HOME is set?")
import random
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("PyCharm Example") \
.getOrCreate()
mi_rango = spark.range(1000).toDF("numero")
mi_rango.show()
# See PyCharm help at https://www.jetbrains.com/help/pycharm/
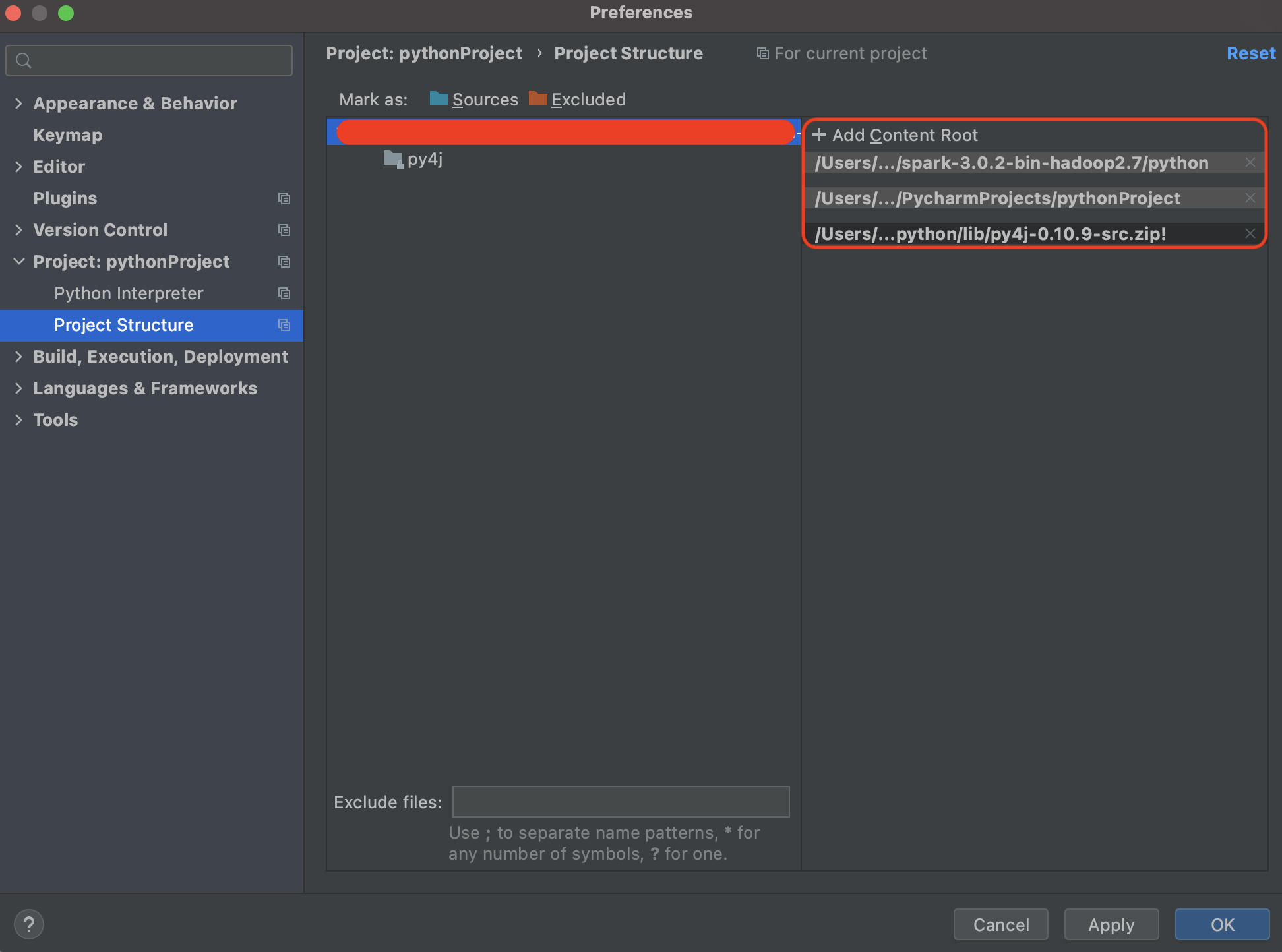
El añadir py4j es una de las alternativas que existen para poder hacer ejecuciones en local del código. Otra alternativa es instalar py4j como dependencia del entorno (environment) y de hecho la misma herramienta te ofrece la alternativa como se refleja en la imagen a continuación
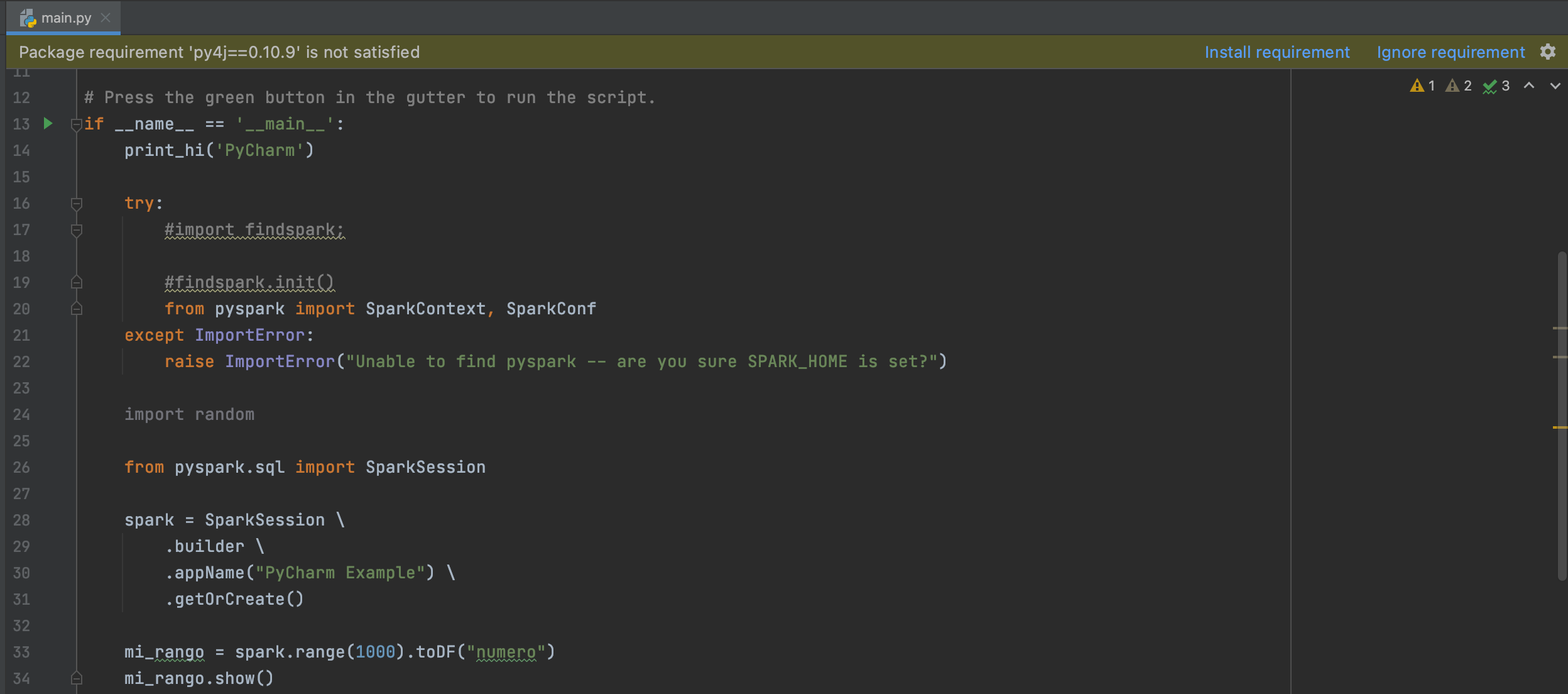
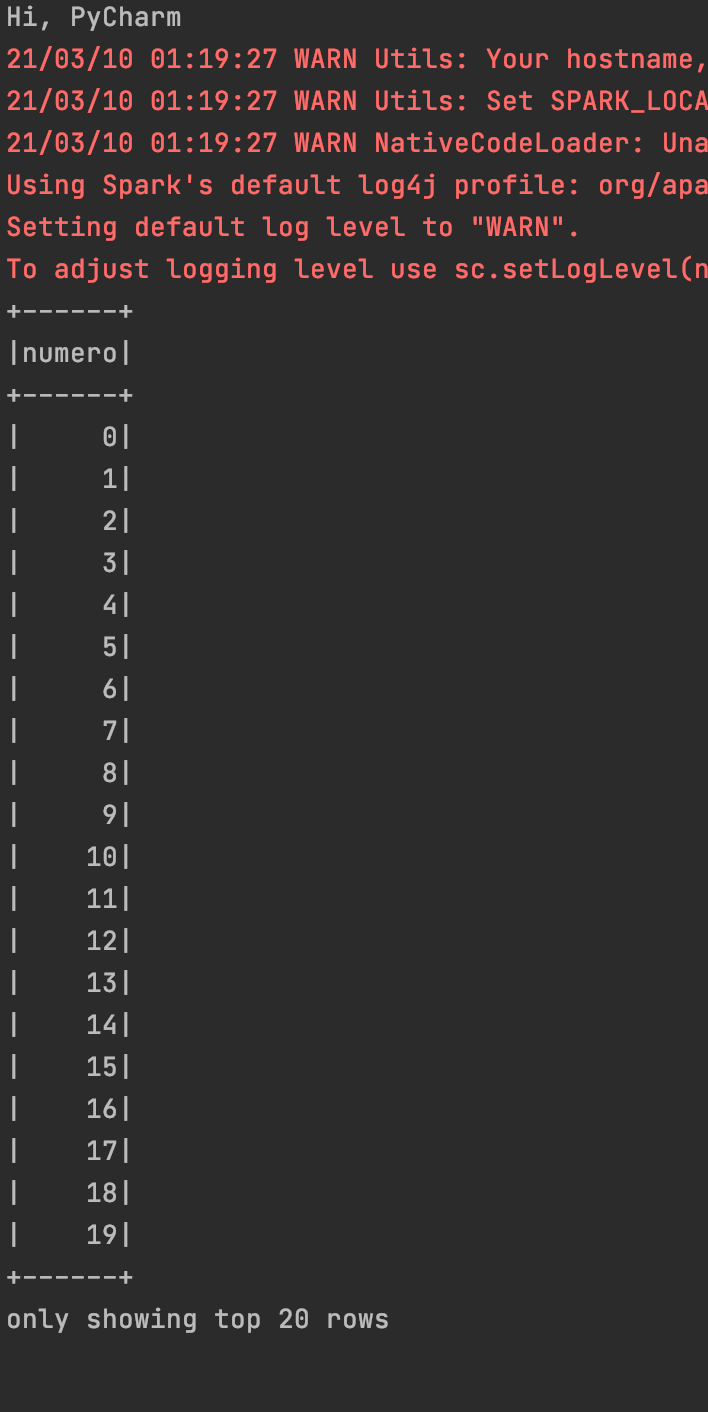
Ahora podemos darnos cuenta que ya no se resaltan (en rojo) parte del código. Procedemos de nuevo a ejecutar el código y nos damos cuenta que este se ejecuta exitosamente.
Ya estamos a punto de terminar pero falta un pequeño detalle, el IDE todavía nos marca unos warnings, por ejemplo el código comentado y esto se debe a que por defecto PyCharm ya aplica PEP8 como estándar al código y por ende todo aquello que no cumpla con el estándar definido será resaltado para su corrección como se muestra en la imagen.
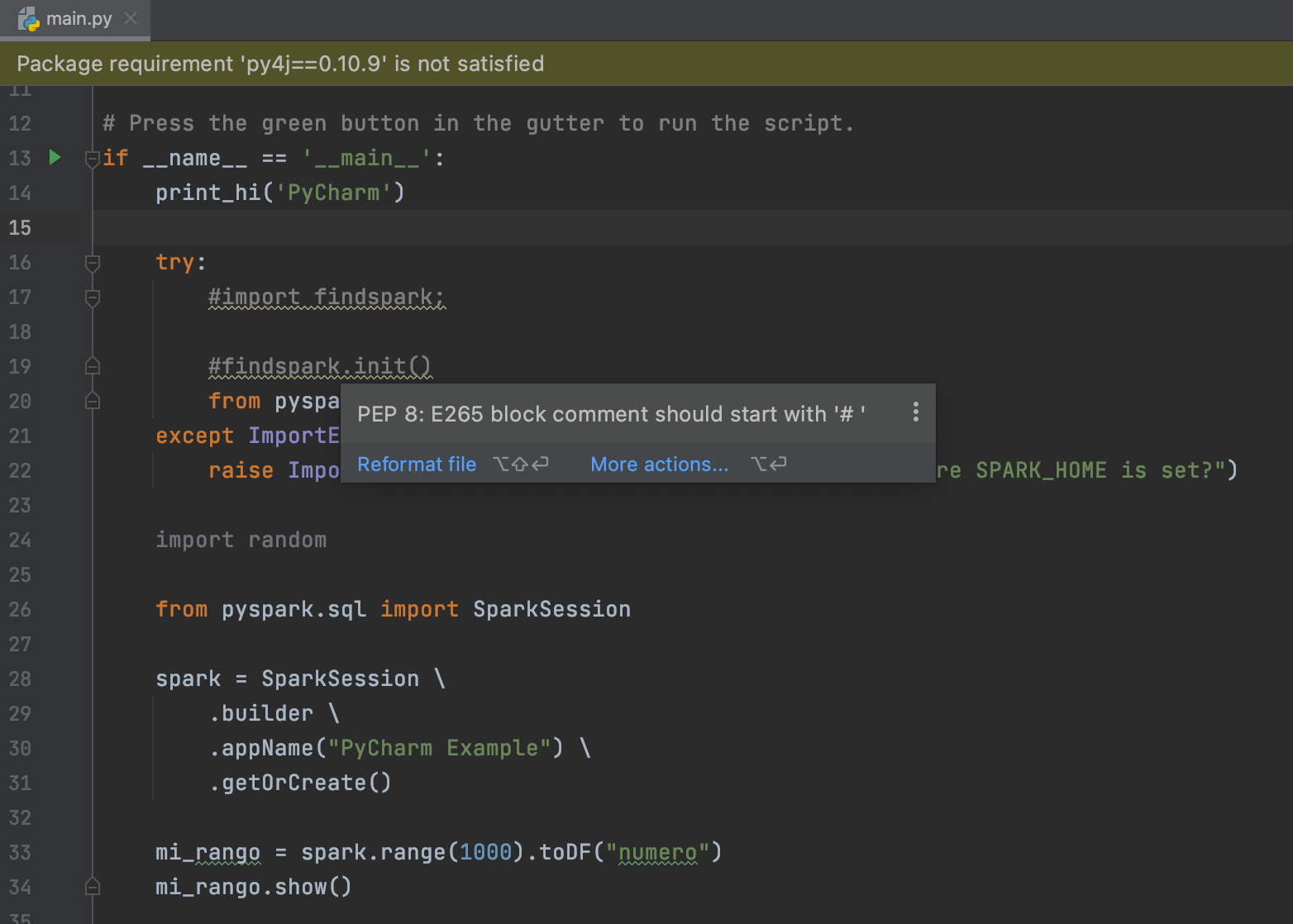
Incluso si hacemos clic en el símbolo de warning (cuidado) ubicado en la parte superior derecha, nos listará las cosas a mejorar que cumplan con el estándar. Una vez listado los warnings procedo mejorar el código quedando de la siguiente manera
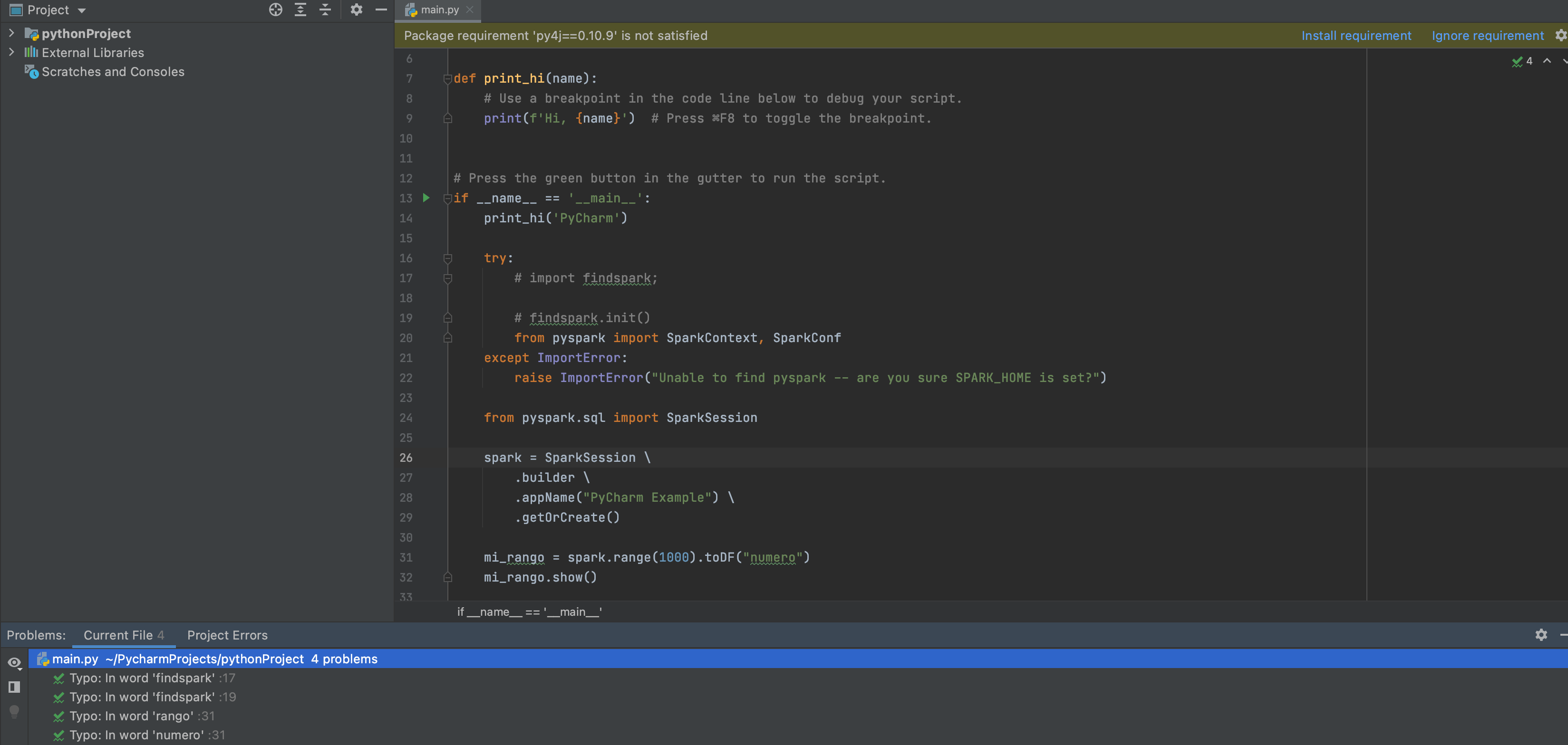
Finalmente el código (aunque es muy simple) ya cumple con el estándar PEP8 y nos ha resultado relativamente sencillo poder ejecutar nuestro código desde el mismo IDE, además la herramienta nos permite sin salir de ella acceder a linea de comandos, hacer control total de Git (pull, push, commit, comparación entre ramas y más), poner breakpoints y realizar debug del código. Otra cosa a comentar es que aun cuando no hayamos definido el SPARK_HOME (cosa que no recomiendo) y el HADOOP_HOME, estas variables podemos definirlas antes de ejecutar el código mediante Edit Configurations.
Ha sido un ejemplo muy simple pero creo que refleja parte del potencial de la herramienta, aunque no todos son buenas noticias, por ejemplo la versión community no permite abrir y ejecutar jupyter notebooks cosa que si permite la versión de pago, llegando incluso a permitir la ejecución celda a celda y esta es una característica muy deseada que algunas herramientas si lo permiten como es el caso de VSCode, sin embargo esto no empaña para nada las capacidades que tiene y puede aportarnos de cara a la productividad.